Understanding Sharding in Elasticsearch
Elasticsearch is extremely scalable due to its distributed architecture. One of the reasons this is the case, is due to something called sharding. If you have worked with other technologies such as relational databases before, then you may have heard of this term.
Before getting into what sharding is, let’s first talk about why it is needed in the first place. Suppose that you have an index containing lots of documents, totalling 1 terabyte of data. You have two nodes in your cluster, each with 512 gigabytes available for storing data. Clearly the entire index will not fit on either of the nodes, so splitting the index’ data up somehow is necessary, or we would effectively be out of disk space.
In scenarios like this where an the size of an index exceeds the hardware limits of a single node, sharding comes to the rescue. Sharding solves this problem by dividing indices into smaller pieces named shards. So a shard will contain a subset of an index’ data and is in itself fully functional and independent, and you can kind of think of a shard as an “independent index.” This is not entirely accurate, hence why I put that in quotation marks, but it’s a decent way to think about it nevertheless. When an index is sharded, a given document within that index will only be stored within one of the shards.
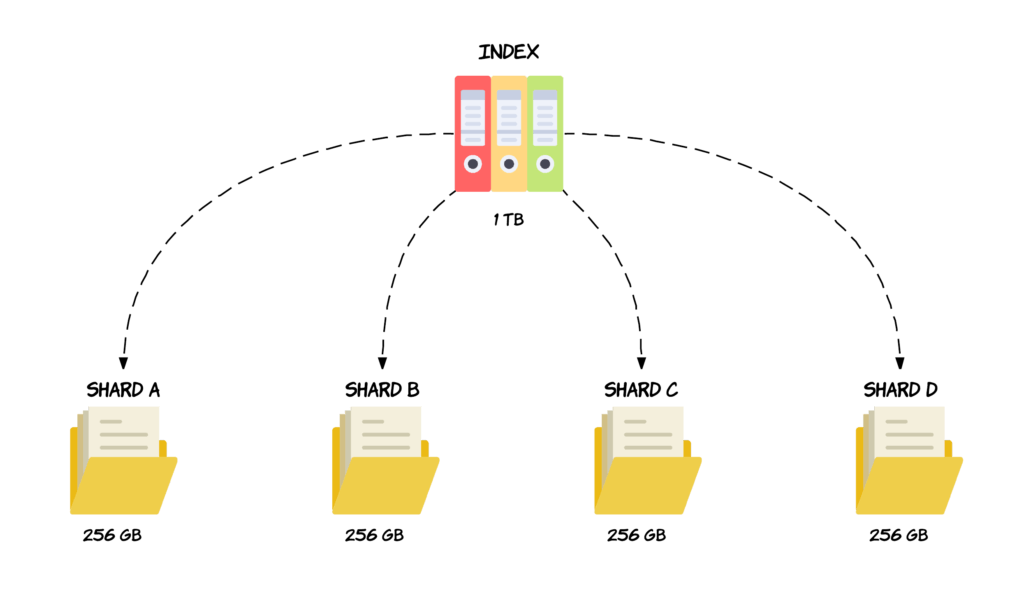
The great thing about shards, is that they can be hosted on any node within the cluster. That being said, an index’ shards will not necessarily be distributed across multiple physical or virtual machines, as this depends on the number of nodes in your cluster. So in the case of the previous example, we could divide the 1 terabyte index into four shards, each containing 256 gigabytes of data, and these shards could then be distributed across the two nodes, meaning that the index as a whole now fits with the disk capacity that we have available.
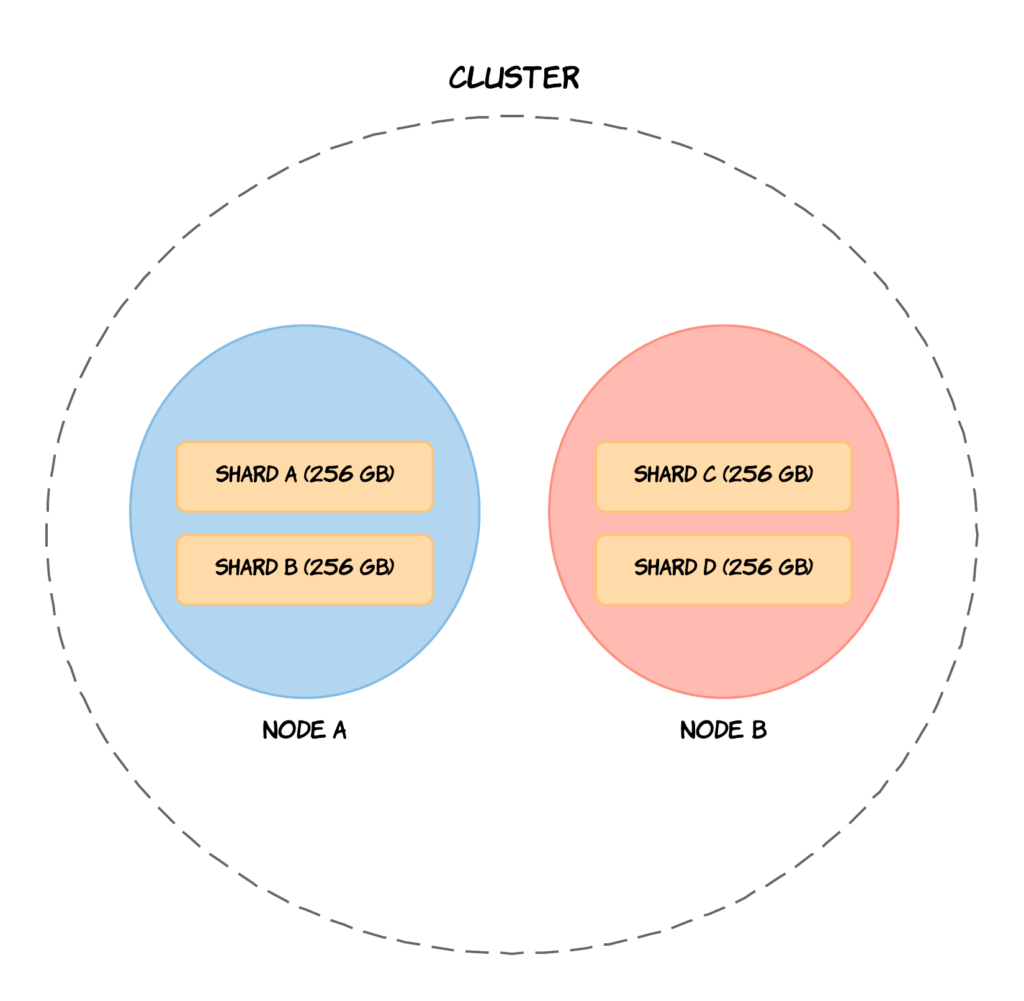
There are two main reasons why sharding is important, with the first one being that it allows you to split and thereby scale volumes of data. So if you have growing amounts of data, you will not face a bottleneck because you can always tweak the number of shards for a particular index. I will get back to how to specify the number of shards in just a moment. The other reason why sharding is important, is that operations can be distributed across multiple nodes and thereby parallelized. This results in increased performance, because multiple machines can potentially work on the same query. This is completely transparent to you as a user of Elasticsearch.
So how do you specify the number of shards an index has? You can optionally specify this at index creation time, but if you don’t, a default number of 5 will be used. This is sufficient in most cases, since it allows for a good amount of growth in data before you need to worry about adding additional shards. How long it will take before you have to worry about that depends on the amount of data that is stored within a particular index and the hardware that you have available, i.e. the number of nodes and the amount of disk space. Of course other indices and their amount of data comes into play as well, so how many shards you want depends on a couple of factors. That being said, a default of 5 shards will get you a long way, and you won’t have to deal with sharding yourself for quite a while unless you are already dealing with large volumes of data.
But what if you do need to change the number of shards for an index? If the index has already been created, you unfortunately cannot change the number of shards. What you would do instead, is to create a new index with the number of shards that you want and move your data over to the new index. Chances are that you will never have to do this if you are a developer, so you typically won’t have to worry about it. Nevertheless, that is how you can change the number of shards for an index if you need to.
So to summarize, sharding is a way of dividing an index’ data volume into smaller parts which are called shards. This enables you to distribute data across multiple nodes within a cluster, meaning that you can store a terabyte of data even if you have no single node with that disk capacity. Sharding also increases performance in cases where shards are distributed on multiple nodes, because search queries can then be parallelized, which better utilizes the hardware resources that your nodes have available to them.
Distributing Documents across Shards (Routing)
You learned how data is stored on potentially more than one node in a cluster, and also how that is accomplished with sharding. But how does Elasticsearch know on which shard to store a new document, and how will it find it when retrieving it by ID? There needs to be a way of determining this, because surely it cannot be random. And also, documents should be distributed evenly between nodes by default, so that we won’t have one shard containing way more documents than another. So determining which shard a given document should be stored in or has been stored is, is called routing.
To make Elasticsearch as easy to use as possible, routing is handled automatically by default, and most users won’t need to manually deal with it. The way it works by default, is that Elasticsearch uses a simple formula for determining the appropriate shard.
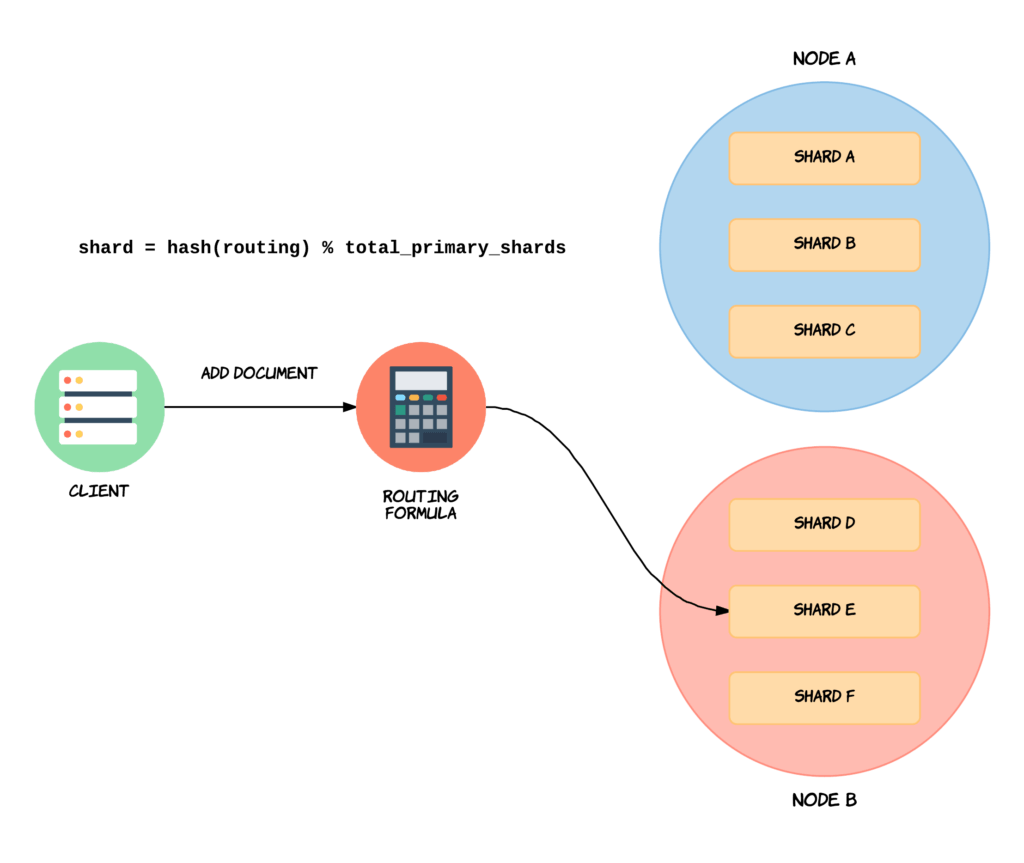
By default, the “routing” value will equal a given document’s ID. This value is then passed through a hashing function, which generates a number that can be used for the division. The remainder of dividing the generated number with the number of primary shards in the index, will give the shard number. This is how Elasticsearch determines the location of specific documents. When executing search queries (i.e. not looking a specific document up by ID), the process is different, as the query is then broadcasted to all shards.
This default behavior ensures that documents are distributed evenly across shards. Since I mentioned that this is the “default behavior,” this of course means that it can be changed. When retrieving, deleting and updating documents, you can specify a custom routing value if you would like to change how documents are distributed. An example of this could be if you have a document for each customer, in which case you could determine the shard based on the customer’s country. In that case, a potential problem could be if the majority of your customers are from the same country, because then the documents would not be evenly spread out across the primary shards. The reason I mention this, is that custom routing is a bit of an advanced topic. While it is easy to do, there are some common pitfalls and things to be aware of, so it should only be used in a production cluster if you know what you are doing. That’s why I am not going to get into that for now. But now you know that the possibility exists.
Remember how I mentioned that the number of shards for an index cannot be changed once an index has been created? Taking the routing formula into consideration, then we have the answer as to why this is the case. If we were to change the number of shards, then the result of running the routing formula would change for documents. Consider an example where a document has been stored on Shard A when we had five shards, because that is what the outcome of the routing formula was at the time. Suppose that we were able to change the number of shards, and that we changed it to seven. If we try to lookup the document by ID, the result of the routing formula might be different. Now the formula might route to Shard B, even though the document is actually stored on Shard A. This means that the document would never be found, and that would really cause some headaches. So that’s why the number of shards cannot be changed once an index has been created, so you would have to create a new index and move the documents to it. The same problem could happen if you introduce custom routing within an existing index that contains documents that have been routed using the default routing formula, so be careful with that!
So the moral of the story is that the default routing formula distributes documents evenly across an index’ primary shards. It is possible to change the routing, but that can cause problems, so that’s a more advanced topic that I won’t get into right now. Routing is also the reason why we cannot change the number of shards for an index that has already been created for the reasons I just mentioned.
What’s Next?
Something different, but kind of related to sharding; replication.
Here is what you will learn:
- The architecture of Elasticsearch
- Mappings and analyzers
- Many kinds of search queries (simple and advanced alike)
- Aggregations, stemming, auto-completion, pagination, filters, fuzzy searches, etc.
- ... and much more!

14 comments on »Understanding Sharding in Elasticsearch«
Thank you so much Andersen. You explained very well and I loved it.
What do you use to create images for your tutorial?
Thanks a lot. This article gave me clarity on terms that just used to pass over head
LucidChart 🙂
Do you have any plans to share things about custom routing? Thanks for explaining about shards :)
Excellent information. Thanks a lot !!
Good explanation about shards.
Thank you.
is it possible to shard an existing not sharded index with data in it?
Well explained!!
Thank You.Very nice explanation
Amazing article and great explanation!
Thanks a lot for the clear explanation
Let’s say there are 4 nodes, each of 256GB as you said.
I indexed all the documents and then one node goes down.
So now if i query for a document which is available on the node which is down,
how will elasticsearch provide us the document?