Understanding Replication in Elasticsearch
In order to understand how replication works in Elasticsearch, you should already understand how sharding works, so be sure to check that out first.
Hardware can fail at any time, and software can be buggy at times. Let’s face it, sometimes things just stop working. The more hardware capacity you add, the higher the risk that some hardware stops working, such as a hard drive breaking. Taking that into consideration, it’s probably a good idea to have some kind of fault tolerance and failover mechanism in place. That’s where replication comes into the picture.
Elasticsearch natively supports replication of your shards, meaning that shards are copied. When a shard is replicated, it is referred to as either a replica shard, or just a replica if you are feeling lazy. The shards that have been replicated are referred to as primary shards. A primary shard and its replicas is referred to as a replication group. Don’t worry too much about this terminology.
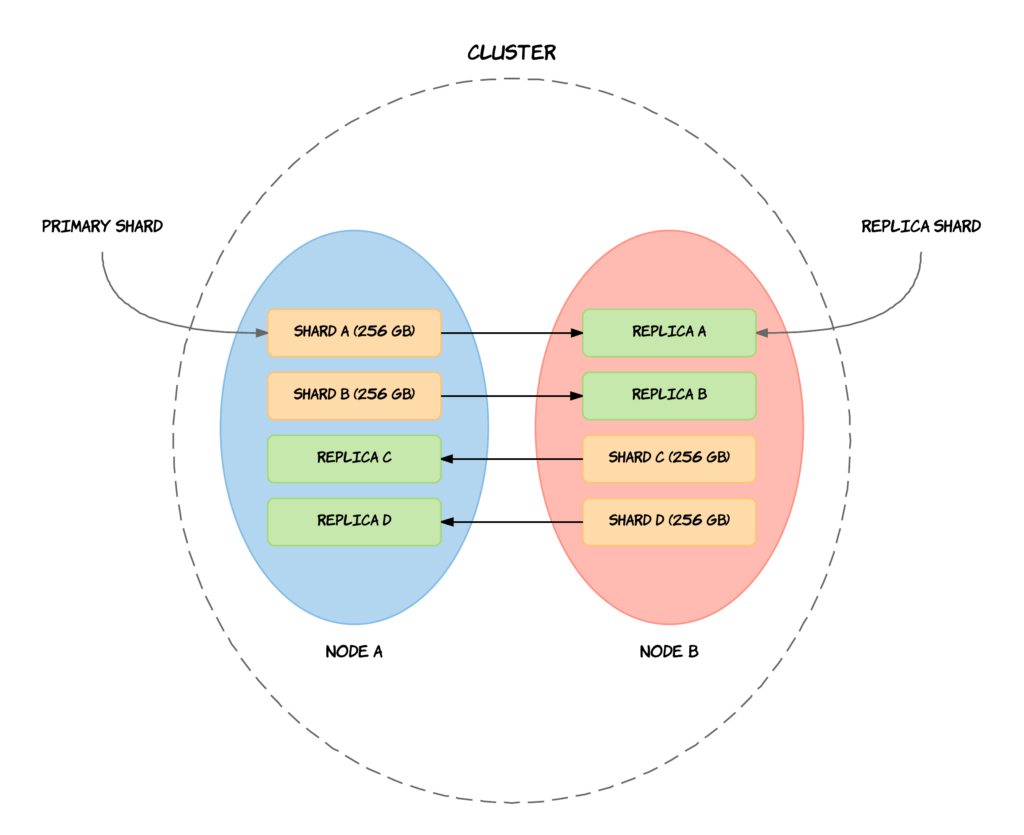
The example that you see above, builds on the example from the introduction to the Elasticsearch architecture with an index of one terabyte divided into four shards of each 256 gigabytes. The shards are now primary shards and each have a replica shard.
Replication serves two purposes, with the main one being to provide high availability in case nodes or shards fail. For replication to even be effective if something goes wrong, replica shards are never allocated to the same nodes as the primary shards, which you can also see on the above diagram. This means that even if an entire node fails, you will have at least one replica of any primary shards on that particular node. The other purpose of replication — or perhaps a side benefit — is increased performance for search queries. This is the case because searches can be executed on all replicas in parallel, meaning that replicas are actually part of the cluster’s searching capabilities. Replicas are therefore not exclusively used for availability purposes, although that is often the primary motivation for using replication.
As with shards, the number of replicas is defined when creating an index. The default number of replicas is one, being one for each shard. This means that by default, a cluster consisting of more than one node, will have 5 primary shards and 5 replicas, totalling 10 shards per index. This makes up a complete replica of your data, so either of the nodes can have a disk failure without you losing any data. The reason I said that the cluster should have more than one node, is that replicas are never stored on the same node as the primary shard that it is a replica of, as I mentioned before.
To sum up, a replica shard or replica is a copy of a shard. A shard with a replica is referred to as a primary shard, and a primary shard and its replicas, is referred to as a replication group. The purpose of replication is both to ensure high availability and to improve search query performance, although the main purpose is often to be more fault tolerant. This is accomplished by never storing a replica shard on the same node as its primary shard. Each shard within an index has a single replica by default, given that the cluster contains more than a single node.
Keeping Replica Shards Synchronized
Okay, so now that you know what replication is along with a couple of details about it, how does it actually work? If a shard is replicated five times, for instance, how are the replicas updated whenever data changes or is removed? Clearly the replicas need to be kept in sync, because otherwise we would run into trouble if a document is deleted from one replica and not from another; in that case, queries would be unpredictable, because the result would depend on which particular replica is read from.
So how does Elasticsearch keep everything in sync? Elasticsearch uses a model named primary-backup for its data replication. This means that the primary shard in a replication group acts as the entry point for indexing operations. Translated into normal English, this means that all operations that affect the index — such as adding, updating, or removing documents — are sent to the primary shard. The primary shard is then responsible for validating the operations and ensuring that everything is good. This involves checking if the request is structurally invalid, such as trying to add a number to an object field or something like that. When the operation has been accepted by the primary shard, the operation will be performed locally on the primary shard itself. When the operation completes, the operation will be forwarded to each of the replica shards in the replica group. If the shard has multiple replicas, the operation will be performed in parallel on each of the replicas. When the operation has completed successfully on every replica and responded to the primary shard, the primary shard will respond to the client that the operation has completed successfully. This is all illustrated in the below diagram.
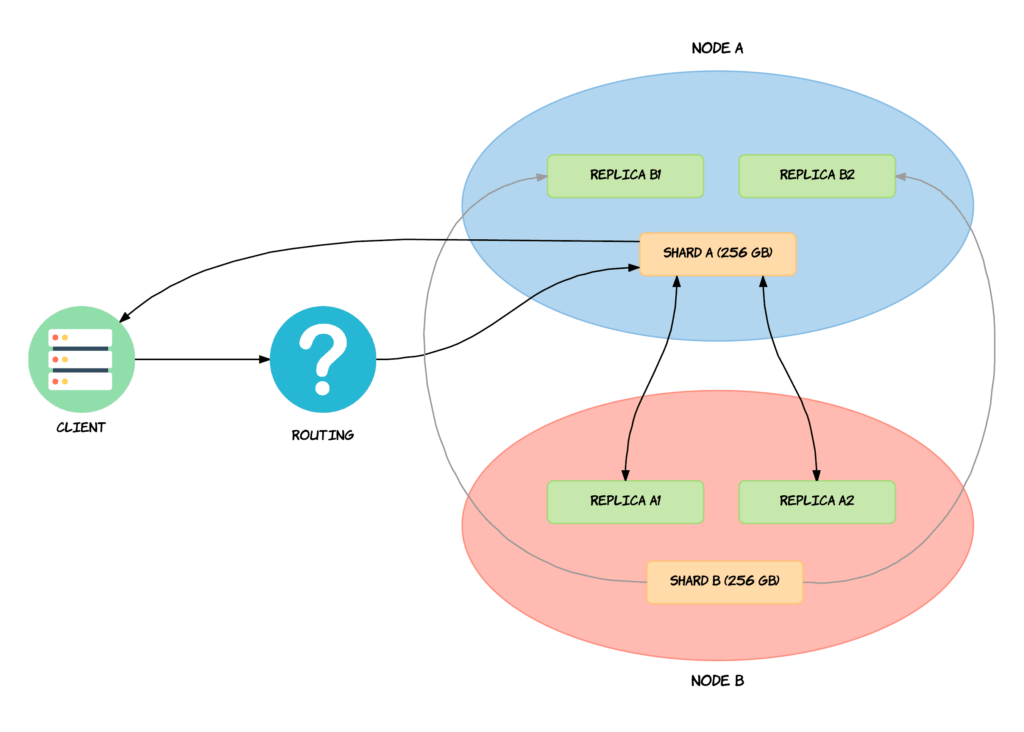
Let’s repeat that one more time while going through a simple example based on the above diagram. We have a cluster with two nodes. We only have a single index consisting of two shards, each with two replicas. We have a client on the left-hand side, which would typically be a server communicating with the cluster. In this case, we want to delete a document from the index. At this point, Elasticsearch needs to find the correct replication group, and thereby also the primary shard. This is done with so-called routing, which is not something that we will get into right now, so you can consider that a black box. Just know that something happens there that finds the appropriate replication group and its primary shard – Shard A in this example. The operation is then routed to the primary shard where it is validated and then executed. Once the operation completes on the primary shard itself, the operation is sent to the replica shards within the replication group. In this case that means that the delete operation is sent to Replica A1 and Replica A2. When the operation successfully completes on both of these replicas, the primary shard — i.e. Shard A — acknowledges that the request was successful to the client.
This example assumes that there is at least one replica for the shards. If there are no replicas, the operation is just executed directly on the shard and that’s all.
Here is what you will learn:
- The architecture of Elasticsearch
- Mappings and analyzers
- Many kinds of search queries (simple and advanced alike)
- Aggregations, stemming, auto-completion, pagination, filters, fuzzy searches, etc.
- ... and much more!

11 comments on »Understanding Replication in Elasticsearch«
Good Article. Thanks.
the moment when client is notified that operation is complete could be configured, isn’t it? So you can get okay from server immediately, without waiting for all replicas. So, it is configurable. Is that correct?
I believe that is possible, but I don’t recall how to do it off the top of my head. I encourage you to dig through the documentation for a parameter that you can send along the request. :-)
Hi,
This is a nice article. Keep it up!!
So according to picture 1, if there are 4 shards (2 Primary and 2 Replica) should we ensure the Node has twice the amount of storage? Assuming Node B fails, then all the indexes should be stored and retrieved from Node A. So in short the higher the number of replica shards, the higher the storage requirement
This is a nice article. Is there any way you can also explain the procedure to setup replication (steps to add additional nodes) ?
Great article. Very clear and concise.
Your second diagram implies that there can be 2 replicas of the same primary shard on the same node. So as long as no replica is present on the primary shard’s node, any replication after that is authorized? Is the goal to improve performance?
In the last example , you said that the two replicas for Shard A , i.e. A1 and A2 are present in the node B . Does it make sense to have two replicas of a same shard on a single node ?
I understand its an example , but is it valid or ideal to have multiple replicas of same shard on a single node ?
Thanks!
Thank you for this simple explanation, but what if a delete document succeed against primary shard and failed against one or more of its replicas ? if this happen should we consider a sync manually ? how? if not does the replication groups sync it self some how?
another thing, how does the routing really works in details ?
Thank you man