Introduction to the Elasticsearch Architecture
This article is an introduction to the physical architecture of Elasticsearch, being how documents are distributed across virtual or physical machines and how machines work together to form what is known as a cluster.
Nodes & Clusters
To start things off, we will begin by talking about nodes and clusters, which are at the centre of the Elasticsearch architecture. A node is a server (either physical or virtual) that stores data and is part of what is called a cluster. A cluster is a collection of nodes, i.e. servers, and each node contains a part of the cluster’s data, being the data that you add to the cluster. The collection of nodes therefore contains the entire data set for the cluster.
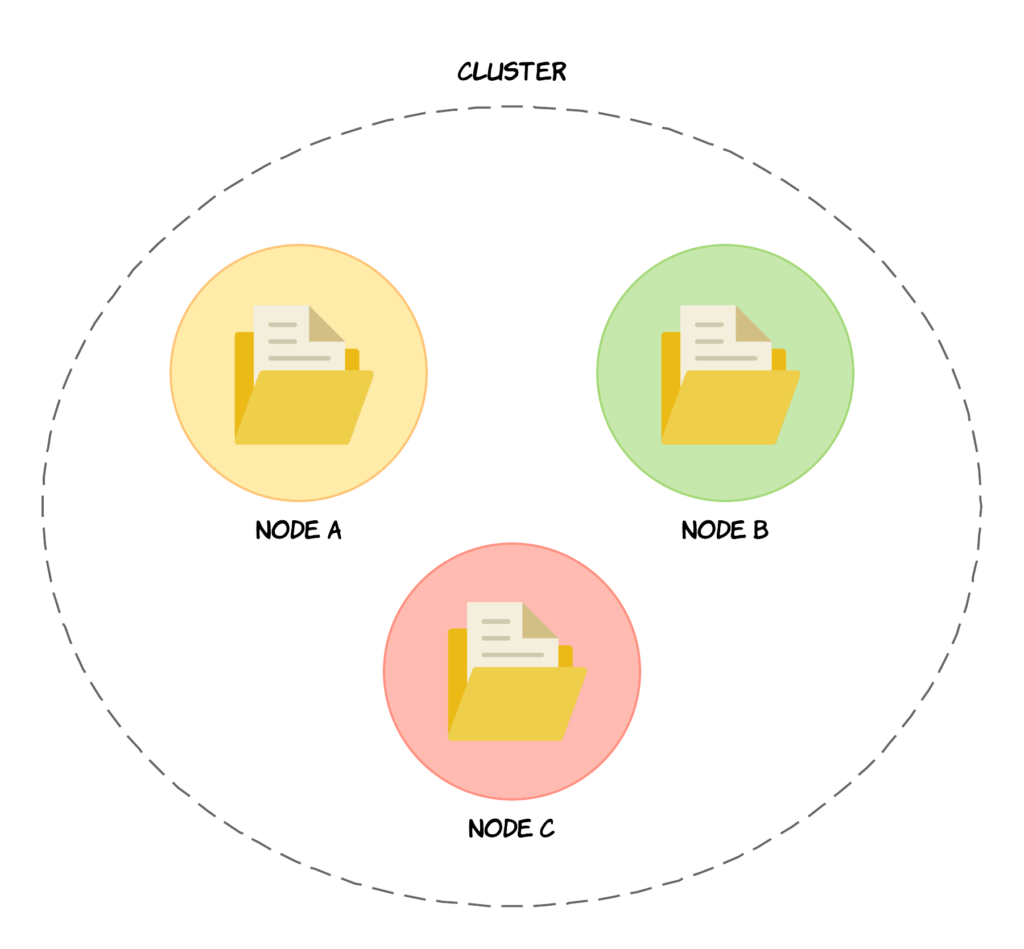
Each node participates in the indexing and searching capabilities of the cluster, meaning that a node will participate in a given search query by searching the data that it stores. For example, you might have some data on Node A and some other data on Node B, and both pieces of data match a given query. The important thing is to understand right now, is that a node contains a part of your data, and the node supports searching this data and indexing new data or manipulating existing data.
Apart from that, it’s also worth knowing that every node within the cluster can handle HTTP requests for clients that want to send a request to the cluster. This is done by using the HTTP REST API that the cluster exposes. A given node then receives this request and will be responsible for coordinating the rest of the work. Also, a given node within the cluster knows about every node in the cluster and is able to forward requests to a given node by using a transport layer, whereas the HTTP layer is exclusively used for communicating with external clients. All of the nodes accept HTTP requests from clients by default.
Each node may also be assigned as being the so-called master node by default. A master node is the node that is responsible for coordinating changes to the cluster, such as adding or removing nodes, creating or removing indices, etc. This master node updates the state of the cluster and it is the only node that may do this. This is not essential to remember for most people, but it is good to know that this is what happens under the hood. There is more to master nodes than this, but this is typically not something that you need to know as a developer.
Both clusters and nodes are identified by unique names. For clusters, the default name is elasticsearch in all lowercase letters, and the default name for nodes is a Universally Unique Identifier, also referred to as a UUID. If you want or need to, you can change this default behavior. The names of nodes are important because that is how you can identify which physical or virtual machines correspond to which Elasticsearch nodes.
By default, nodes join a cluster named elasticsearch, but you can configure nodes to join a specific cluster by specifying its name. However, the default behavior means that if you start up a number of nodes on your network, they will automatically join a cluster named elasticsearch. And, if no cluster already exists with that name, it will be formed. Therefore it is a good idea to change the default name in a production environment, just to make sure that no nodes accidentally join a production cluster, for instance while performing maintenance on the cluster or while developing on the same network. Hopefully your development machine is not running on the same network as a production setup, but it is good practice just in case.
You can have as many nodes running within a cluster that you want, and it is perfectly valid to have a cluster with only one node. The architecture of Elasticsearch is extremely scalable, particularly due to sharding, so scalability is not going to be an issue for you unless you are dealing with huge amounts of data. There are clusters out there with several terabytes of data, so chances are that this won’t be a problem for you.
Those were the very basics of the Elasticsearch architecture in terms of the network and physical/virtual machines, but there is of course more to it than this. More on that later. Let’s now move on to talking about how data is stored within a cluster.
Indices & Documents
Now that you know what clusters and nodes are, let’s take a closer look at how data is organized and stored. Each data item that you store within your cluster is called a document, being a basic unit of information that can be indexed. Documents are JSON objects and would correspond to rows in a relational database. So if you wanted to store a person, you could add an object with the name and country properties. But where are these JSON objects stored then? You already know that data is stored across all of the nodes in the cluster, but how are the documents organized? Documents are stored within something called indices. An index is a collection of documents that have somewhat similar characteristics, i.e. are logically related. An example would be to have an index for product data, one for customer data, and one for orders.
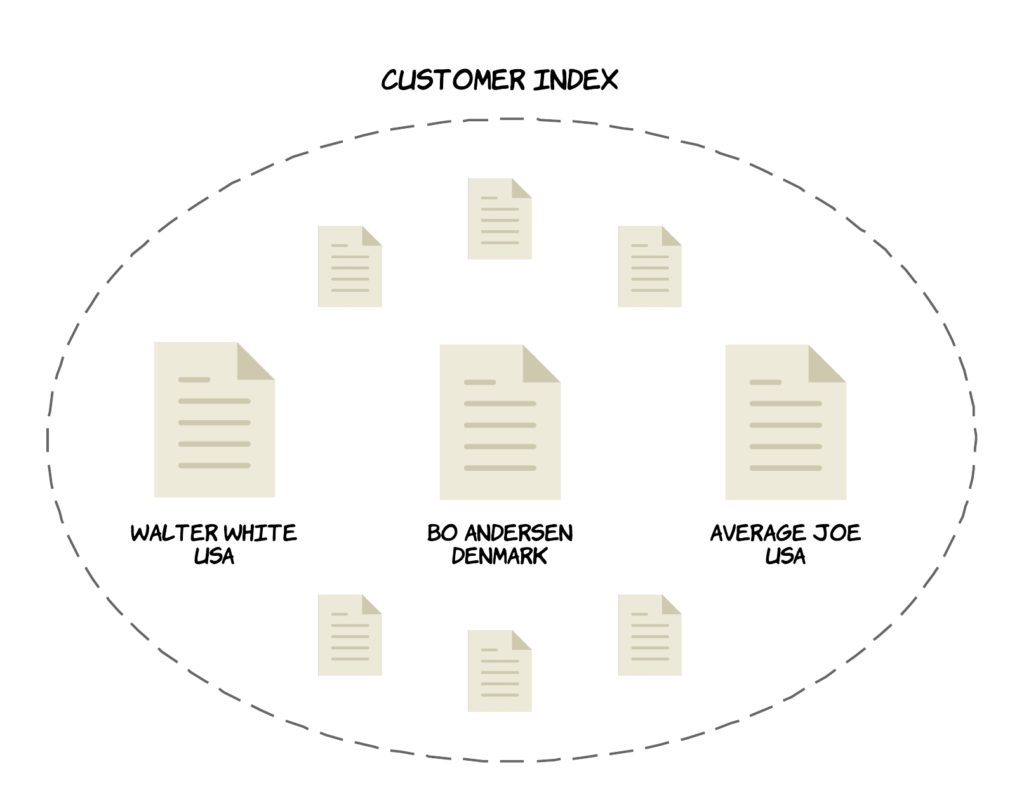
Documents have IDs assigned to them either automatically by Elasticsearch, or by you when adding them to an index. A document is uniquely identified by the index and its ID. You can add as many documents as you want to an index.
As with clusters and nodes, indices are also identified by names, which must be in all lowercased letters. These names are then used when searching for documents, in which case you would specify the index to search through for matching documents. The same applies for adding, removing and updating documents.
So to recap; documents are added to indices, and indices are a collection of documents, with the documents themselves being JSON objects.
What’s Next?
Those were the very basics of the Elasticsearch architecture, but there is more to it than that. The next logical step, is to learn about sharding in Elasticsearch.
Here is what you will learn:
- The architecture of Elasticsearch
- Mappings and analyzers
- Many kinds of search queries (simple and advanced alike)
- Aggregations, stemming, auto-completion, pagination, filters, fuzzy searches, etc.
- ... and much more!

3 comments on »Introduction to the Elasticsearch Architecture«
Very nicely explained in simple way. This shows that you are also from opensource community. keep it up.
Thanks
Highly useful !
Just a comment… many indexing tools find the original objects (in other storage, databases…), and the index builds references to them, not a physical copy of the properties.
I can imagine ElasticSearch uses a different idea for indexing, where you have to decide (by explicit calls) what to store, and make a copy of (part of) the original object. Much more as a cache, not a ‘classical index’. Is this true ?