Understanding the Inverted Index in Elasticsearch
If you read how analyzers work in Elasticsearch prior to reading this post, then you know how Elasticsearch analyzes text fields. Then you might wonder what actually happens with the results of the analysis process. They must end up being stored somewhere, right, because otherwise what’s the point? The results from the analysis are indeed stored somewhere; within something called an inverted index. That sounds very fancy and abstract, but once I show you a simple illustration, you will see that it’s actually not that complicated.
The purpose of an inverted index, is to store text in a structure that allows for very efficient and fast full-text searches. When performing full-text searches, we are actually querying an inverted index and not the JSON documents that we defined when indexing the documents. The reason why I say an inverted index, is because a cluster will have at least one inverted index. That’s because there will be an inverted index for each full-text field per index. So if you have an index containing documents that contain five full-text fields, you will have five inverted indices.
An inverted index consists of all of the unique terms that appear in any document covered by the index. For each term, the list of documents in which the term appears, is stored. So essentially an inverted index is a mapping between terms and which documents contain those terms. Since an inverted index works at the document field level and stores the terms for a given field, it doesn’t need to deal with different fields. So what you will see in the following example is at the scope of a specific field.
Alright, so let’s see an example. Suppose that we have two recipes with the following titles: “The Best Pasta Recipe with Pesto” and “Delicious Pasta Carbonara Recipe.” The following table shows what the inverted index would look like.
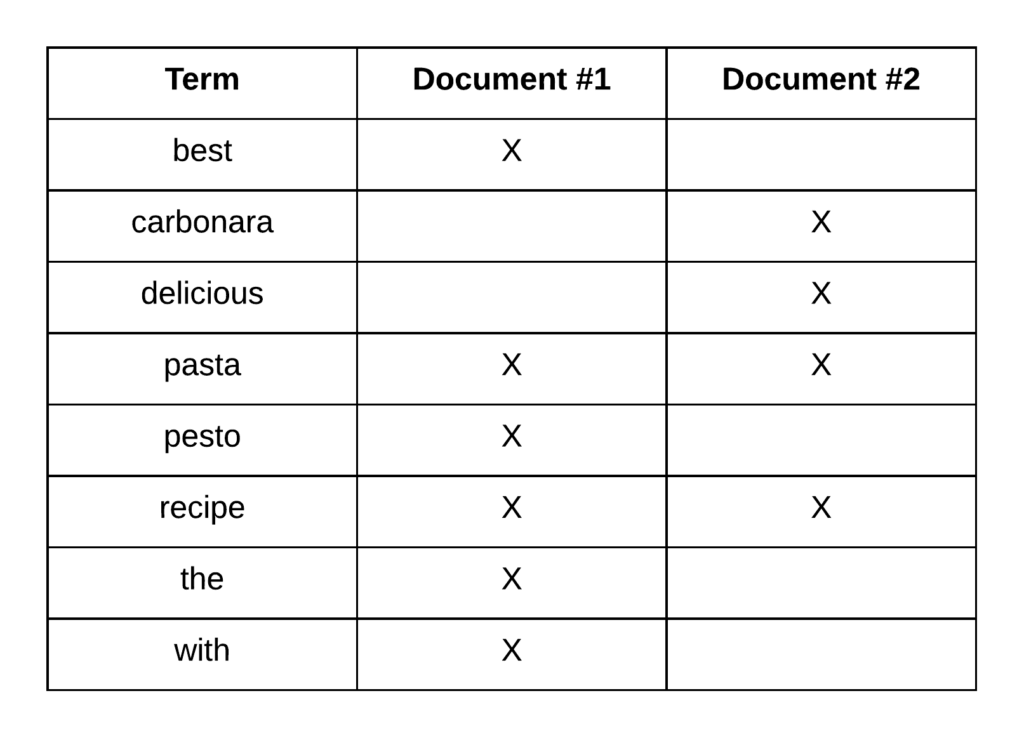
So the terms from both of the titles have been added to the index. For each term, we can see which document contains the term, which enables Elasticsearch to efficiently match documents containing specific terms. A part of what makes this possible, is that the terms are sorted. Also notice that the terms within the index are the results of the analysis process that you saw in the previous post in case you read that one. So most symbols have been removed at this point, and characters have been lowercased. This of course depends on the analyzer that was used, but that will often be the standard analyzer.
Performing a search involves a lot of things such as relevance, but let’s forget about that for now. The first step of a search query is to find the documents that match the query in the first place. So if we were to search for “pasta recipe,” we would see that both documents contain both terms.

If we searched for “delicious recipe,” the results would be as follows.

Like I mentioned before, this is of course an oversimplification of how searching works, but I just wanted to show you the general idea of how the inverted index is used when performing search queries. It’s great to know how it works, but this is all transparent to you as a user of Elasticsearch, and you won’t have to actively deal with the inverted index; it’s just something that Elasticsearch uses internally. That being said, it is very beneficial to know the basics of how it works for a number of reasons.
The inverted index also holds information that is used internally, such as for computing relevance. Some examples of this could be the number of documents containing each term, the number of times a term appears in a given document, the average length of a field, etc.
It is also possible to apply stemming of words and synonyms. This would also be applied to the inverted index, but I wanted to keep things simple in this basic walkthrough of the inverted index.
So to briefly recap what we talked about in this post… An analyzer is applied to full-text fields, and the results of this analysis process are stored within an inverted index. An inverted index consists of all of the terms for a given field across all documents within an index. So when performing a search query, we are not actually searching the documents themselves, but rather an inverted index. This is important to understand because otherwise you might be left puzzled as to why some queries don’t match what you expect.
Here is what you will learn:
- The architecture of Elasticsearch
- Mappings and analyzers
- Many kinds of search queries (simple and advanced alike)
- Aggregations, stemming, auto-completion, pagination, filters, fuzzy searches, etc.
- ... and much more!

2 comments on »Understanding the Inverted Index in Elasticsearch«
I really loved the way you have explained the stuff ! Really helpful.
That was very briefly explained.
Please let me know if you have a blog related to search for case sensitive terms.